✍Наша Модель для Расстановки Знаков Препинания и Прописных Букв
Полную версию статьи-релиза вы можете прочитать здесь. Сама модель живет тут:
 snakers4
snakers4При разработке систем распознавания речи мы сталкиваемся с заблуждениями среди потребителей и разработчиков, в первую очередь связанными с разделением формы и сути. Одним из таких заблуждений является то, что в устной речи якобы "можно услышать" грамматически верные знаки препинания и пробелы между словами, когда по факту реальная устная речь и грамотная письменная речь очень сильно отличаются (устная речь скорее похожа на "поток" слегка разделенный паузами и интонацией, поэтому люди так не любят монотонно бубнящих докладчиков).
Понятно, что можно просто начинать каждое высказывание с большой буквы и ставить точку в конце. Но хотелось бы иметь какое-то относительно простое и универсальное средство расстановки знаков препинания и заглавных букв в предложениях, которые генерирует наша система распознавания речи. Совсем хорошо бы было, если бы такая система в принципе работала с любыми текстами.
По этой причине мы бы хотели поделиться с сообществом системой, которая:
- Расставляет заглавные буквы и основные знаки препинания (точка, запятая, дефис, вопросительный знак, восклицательный знак, тире для русского языка);
- Работает на 4 языках (русский, английский, немецкий, испанский);
- По построению должна работать максимально абстрактно на любом тексте и не основана на каких-то фиксированных правилах;
- Имеет минимальные нетривиальные метрики и выполняет задачу улучшения читабельности текста;
На всякий случай явно повторюсь — цель такой системы — лишь улучшать читабельность текста. Она не добавляет в текст информации, которой в нем изначально не было.
Как Попробовать
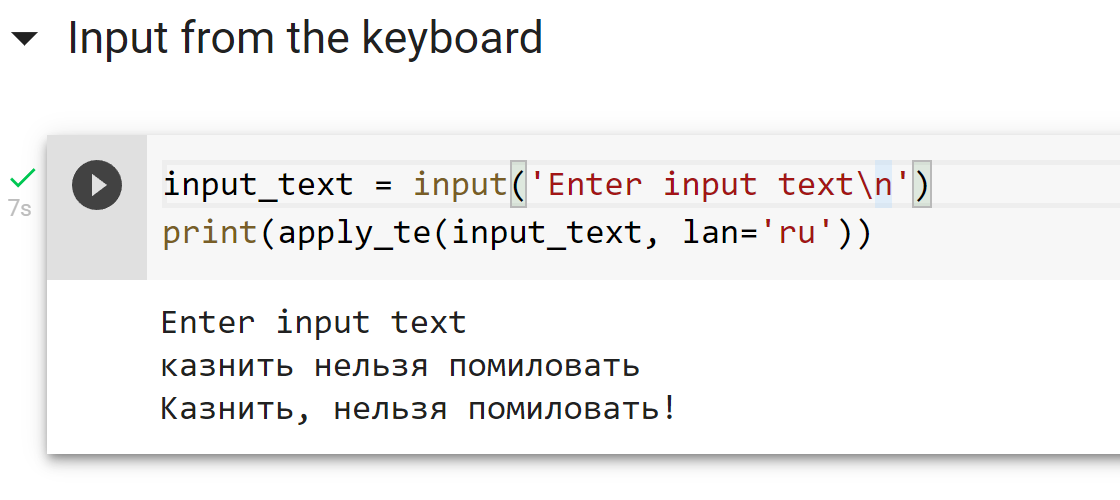
Модель выложена в репозитории проекта silero-models и, соответственно, будет поддерживаться, как и прочие наши решения оттуда. А вот простой запуск модели (с более подробными примерами можно ознакомиться в colab):
import torch
model, example_texts, languages, punct, apply_te = torch.hub.load(repo_or_dir='snakers4/silero-models', model='silero_te')
input_text = input('Enter input text\n')
apply_te(input_text, lan='en')


Ограничения
У данной работы есть ряд ограничений и очевидных вещей, которые мы решили пока не делать (так сказать нужно же было где-то поставить точку):
- На языках кроме английского модель сносно работает с длинными предложениями. Но разделять несколько предложений или целые параграфы текста на отдельные предложения она по построению пока не умеет;
- Не совсем понятно как делить на предложения целые "книги" и неясно нужно ли это вообще в принципе;
- Мы не применили факторизацию и структурированный прунинг к модели (например снижение числа голов в механизме внимания);
Нам более-менее очевидно, как сделать большую часть этих вещей, но только время и разведка боем покажет востребованность подобного рода инструментов.