🚀 Ускоряем и Делаем нашу Систему STT Более Компактной - Продолжение
Тут пожалуй только хотел довести до логического завершения то, что начал. Есть еще идеи, как сделать саму систему в пару раз легче и существенно все упростить, но напишем об этом когда сделаем!
Если довести квантизацию до конца, то пока в модельных условиях можно получить такие относительные падения времени обработки данных (все тесты сделаны на 100 аудио 10 секундной длины):
| Batch size | Add partial int8 | Add fusion | Add full Int8 | Total |
|---|---|---|---|---|
| 1 | 14% | 4% | 21% | 42% |
| 5 | 16% | 15% | 12% | 48% |
| 10 | 15% | 14% | 8% | 41% |
| 25 | 15% | 20% | 4% | 44% |
Все результаты в этой таблице - это последовательные относительные приросты путем постепенного накручивания фич (то есть их можно и нужно складывать). Вообще довольно неплохо при прочих равных получить ускорение почти в 2 раза (то есть снижение времени на 50%).
Посмотрим как они будут вести себя в реальном продакшене на реальных многоядерных серверах. Также мы запилили ряд фич при тренировке моделей, которые должны сделать модели еще более устойчивыми к шуму.
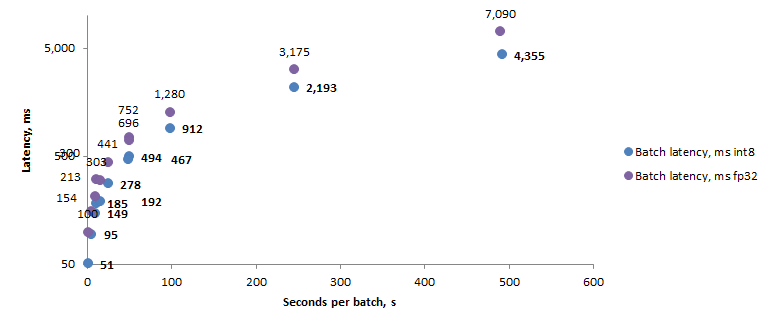
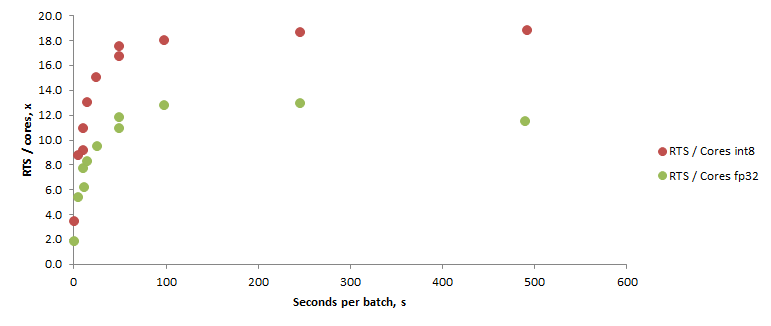
И еще немного графиков
И если вы не заскучали, то вот еще немного красивых графиков.