🚀 Ускоряем и Делаем нашу Систему STT Более Компактной
Сложность измерения скорости систем STT
Все тренды, описанные в этой статье имеют место на момент ее написания. Если вы из будущего и процессора Xeon подешевели, не обессудьте. Прошлая статья на эту тему:
 Alexander Veysov
Alexander Veysov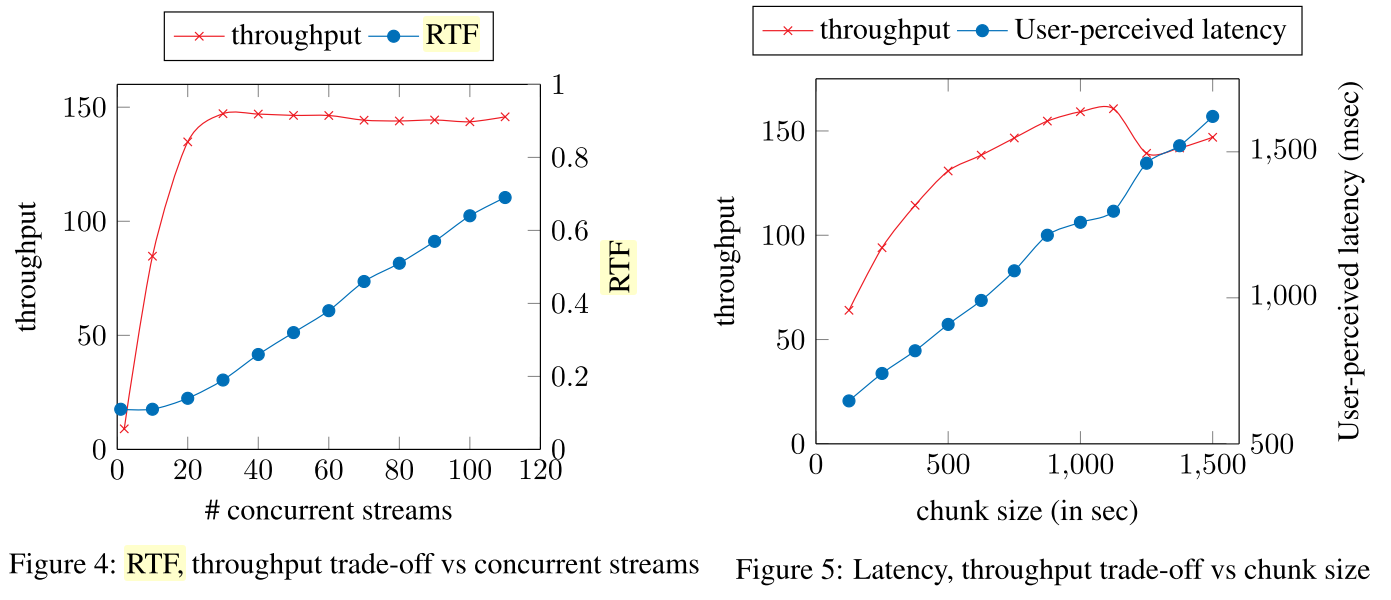
Оценка скорости системы STT - довольно противоречивая вещь. Хотя бы по той причине, что все вендоры прямо заинтересованы несколько завышать свои цифры в процессе продаж. То есть на самом деле, реально единственный способ измерить скорость, это купить все решения на рынке, которые ориентированы хоть на какой-то high load и протестировать. Понятное дело, что это все на совести менеджеров каждой компании, т.к. ресурс на проверку "маркетинговых заявлений" как правило бывает в 10 раз больше, чем профит от такой проверки.
Единственный более менее вменяемый выход - публиковать достаточно простые, прикладные и понятные метрики, чтобы было понятно, что взять их с потолка сильно сложнее, чем просто сказать правду.
RTS это немного самопальная метрика, показывающая сколько секунд моно-аудио можно обработать в секунду, например 1 секунду аудио за 1 секунду работы сетки. В литературе, как правило, используется RTF = 1 / RTS. Не вижу особой разницы, но целые числа приятнее глазу.
Так, например, в процессе биздева мы общались с одним потребителем STT. Проверенный вендор, который давно присутствует на рынке, называл цифру в 6 RTS на ядро именно по распознаванию аудио (если пересчитать заявленные потоки аудио в скорость). Довольно впечатляющий результат, не так ли? У FAIR, например, в их bleeding edge системе оптимальная цифра в районе 8 на ядро. На практике конечно оказывается, что "ну 50% времени же человек не говорит, а слушает".
Если чуть более серьезно, то как мы раньше писали тут, скорость систем очень сложно сравнивать, потому что:
- Метрики throughput и latency очень сильно по-разному балансируются для CPU-based и GPU-based решений и всегда можно показать что-то одно и умолчать другое;
- Что лучше 48 ядер по 2 GHz или 24 ядра по 4+GHz?;
- Никогда не знаешь, приведены ли настоящие production метрики или не имеющие никакого отношения к реальности академические изыскания. Академики обычно очень любят указывать "точность" без привязки к скорости работы. В продакшен системах наоборот - никто не говорит про "точность", но все говорят про скорость;
Alexander VeysovУскоряем нашу систему на CPU - мотивация
Не секрет, чтобы получить хороший результат, надо попытаться получить сначала отличный результат. Когда мы дошли до качества продакшен уровня, в принципе скорость работы нашей системы на CPU была вполне удовлетворительна, но мы явно не оптимизировали эту метрику.
Но в какой-то момент посчитав требования к железу для нескольких проектов, мы пришли к ряду выводов:
- Поскольку рынок анализа и распознавания речи по сути в СНГ находится в младенческой стадии, никто всерьез не задумывался над тем, чтобы покупать для этого эффективное специализированное железо. Но есть много legacy серверов с большим количеством слабых ядер (2.4 - 2.7 GHz). В таких серверах еще как правило можно найти место под однослотовую видеокарту;
- Из однослотовых карт на рынке есть довольно заманчивые предложения от PNY и HP. Памяти и скорости там хватает для любых адекватных моделей, они тонкие и TDP "всего лишь" 100 - 150 Ватт, что скорее всего не будет проблемой;
- Как бы быстро ни работали модели на CPU (пусть даже на уровне bleeding edge) - с ростом нагрузки при расчете на CPU пропускная способность (throughput) растет прямо пропорционально ... числу процессоров (а точнее суммарному числу ядер в них). А многоядерные серверные процессора, особенно Intel, особенно новые и новых архитектур продаются с конской маржой (отличие в цене в 2-3 раза!) по сравнению с эквивалентными по вычислительной мощности решениями от Nvidia или AMD. Понятно, что всегда можно набрать нужное число ядер на сокете 1151, но получится много железок, а это как минимум неудобно;
- Какой бы быстрой ни была модель, GPU для инференса + даже слабые процессора позволяют иметь кратно меньшее количество серверов по сравнению со сценарием деплоя только на CPU (если вам интересны конкретные расчеты под ваш случай - пишите нам напрямую);
- В случае деплоя на CPU количество требуемых серверов растет пропорционально числу ядер. Тут довольно простая арифметика - в сервер помещается 1-2 процессора;
Поэтому неудивительно, что в какой-то момент мы собрались сделать более быструю версию нашей модели, ориентированную только на деплой на CPU.
Ускоряем нашу систему на CPU - результат
Как показала практика в случае работы с GPU до определенного уровня можно позволить себе модели побольше. Но в случае работы с CPU наоборот. Из прикладных "доказанных в бою" реально работающих методов ускорения моделей я знаю реально только два:
- Сделать модель меньше;
- Квантизация;
Мы сделали обе эти вещи, и хоть сравнение с большой моделью тут уже не совсем правильно (она стала больше по сравнению с прошлым разом), но порядок цифр тут передается верно (это не финальный результат, а скорее proof-of-concept, поэтому метрики у такой модели чуть хуже по сравнению с большой, пока не публикуем их, опубликуем метрики финальной маленькой модели, которая пойдет в продакшен):
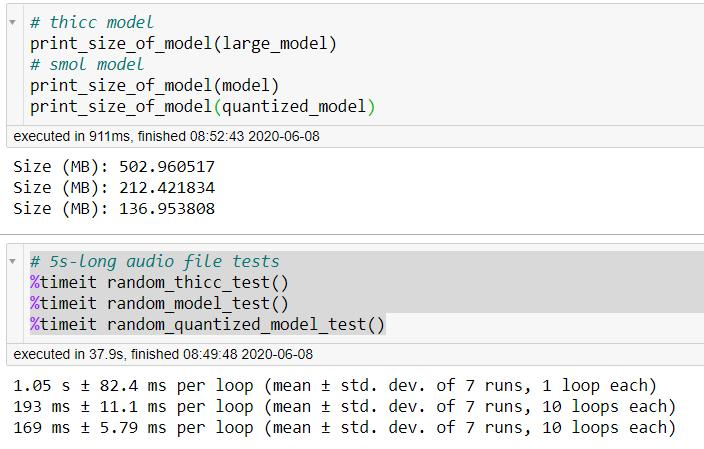
По ряду причин, не получилось квантизовать всю модель целиком, но даже частичная квантизация дала интересный артефакт - если раньше большие модели на CPU не особо хорошо реагировали на размер батча, то сейчас появились интересные зависимости - модель стала насыщаться на более высоких показателях RTS.

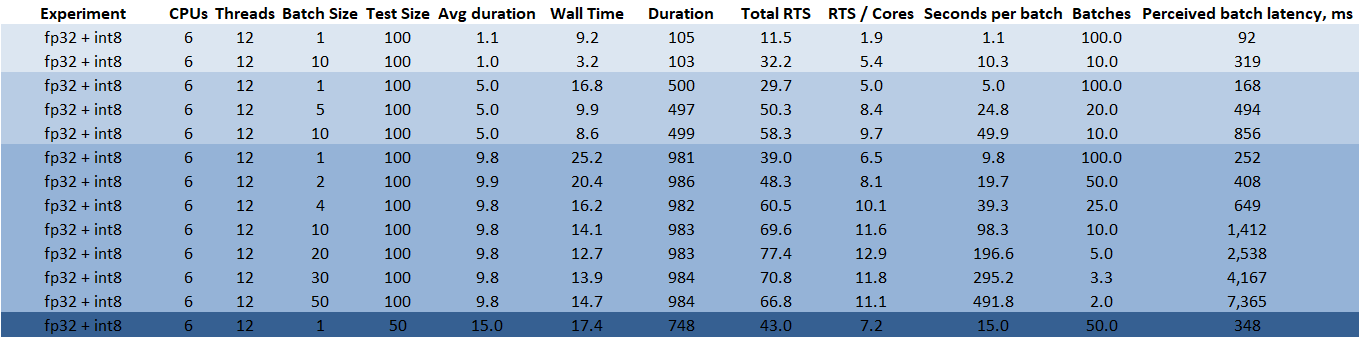
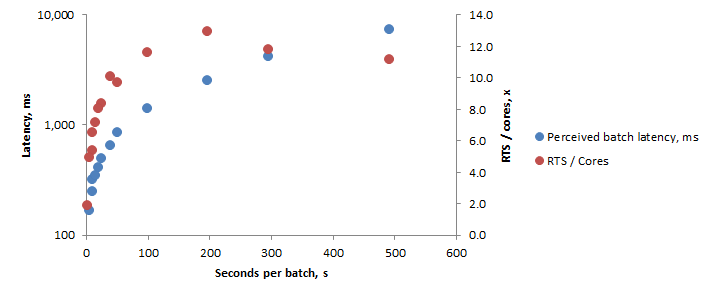
Получается, что даже на CPU сценарии использования модели четко делятся на несколько типов:
- Если нужно получить ультра-быстрые ответы (100-200ms) даже на CPU - можно собирать короткие кусочки в батчи по несколько штук;
- Оптимизируем latency - грузим маленькие кусочки аудио (2-3с) небольшими батчами (3-5 штук);
- Оптимизируем throughput - просто линейно увеличиваем размер батча в секундах, длина каждого кусочка не особо важна;
- Никто не мешает иметь по несколько воркеров каждого типа на одном сервере и просто сделать изоляцию ядер на уровне контейнеров;
Также интересно что будет, если в таком тесте увеличить количество ядер и / или их тактовую частоту - скорее всего оптимальный пик длины батча в секундах будет смещается влево, а latency просто станет ниже для всех экспериментов. И финальная ремарка - нигде в этой статье я не говорил про пост-процессинг, но в текущей парадигме он решается чисто архитектурно, вычислительная мощность там почти не требуется.