📦 Мажорный Релиз Enterprise Дистрибутивов v1.4.4 и релиз STT моделей v15
Мы очень много работали с потоковым распознаванием и улучшением наших моделей распознавания языка. Нельзя выделить одну "главную" фичу, было очень много точечной работы в первую очередь над детектором аудио и потоковым распознаванием.
📦 Релиз Enterprise Дистрибутивов v1.4.4
Начиная с внутренней версии 1.4.1 мы активно обкатывали свои дистрибутивы на своих внутренних продуктах (телеграм-бот и сервис для распознавания аудио) и вместе с нашими партнерами.
Просуммируем что мы добавили с точки зрения пакетирования во время промежуточных релизов с 1.4.1 по 1.4.4.
Общее:
- Добавлена поддержка работы с 2 LM для других языков;
- Добавлена возможности работы с другими языками;
- Старые лиц. файлы и дистрибутивы совместимы с новыми образами;
gRPC:
- Масштабный релиз нашего VAD-а, он теперь встроен и в gRPC АПИ;
- Добавлена модель расстановки знаков препинания и пунктуации (te-model);
- Дальнейшие фиксы проблем VAD-а в начале и конце сессии ("спасибо", лишняя обрезка, повышена точность определения границ речи);
- Существенно снижено потребление ресурсов VAD-ом, убраны разные его разновидности, на порядок снижено количество кода для вызова непосредственно самого VAD-а;
- Рефакторинг и существенное упрощение логики работы VAD-а;
- Масштабная переработка параметров VAD-а, добавлена возможности указывать их не только при старте сервиса, но и в каждой gRPC сессии;
- Добавлена поддержка SSL в gRPC API без возни с сертификатами;
- Возможность изменять адрес api консюмера в gRPC через .env переменные:
API_NAME- по умолчанию, 'api',API_PORT- по умолчанию, '5000'; - Нагрузочное тестирование gRPC на длинных файлах на больших объемах при стресс тестах, блуждающие ошибки самого gRPC локализованы и устранены, утечки памяти найдены и устранены;
- Нашли и пофиксили в gRPC критичный баг, который при одновременном прогоне нескольких длинных файлов иногда приводил к странным ошибкам и падению всего контейнера;
Основное API:
- Для te-model вынесен отдельный эндпоинт в основное АПИ;
- Фикс тупого бага в диаризации;
TTS:
- Новое обязательное поле в запросе в
/voiceметод -sample_rate; - Добавили TTS-only compose file;
- Обновили доку;
- Финишная прямая перед масштабным релизом синтеза;
💎 Релиз новых моделей V15
Изначально планировалось, что релизы дистрибутивов и моделей будут иметь одну мажорную версию, но они разошлись (мы пропустили одну версию, в будущем синхронизируемся, потому что будем сильно менять наши модели, и это займет время).
Обновление от 07.04.2022 - сделали ручную переразметку "новых" валидационных сетов.
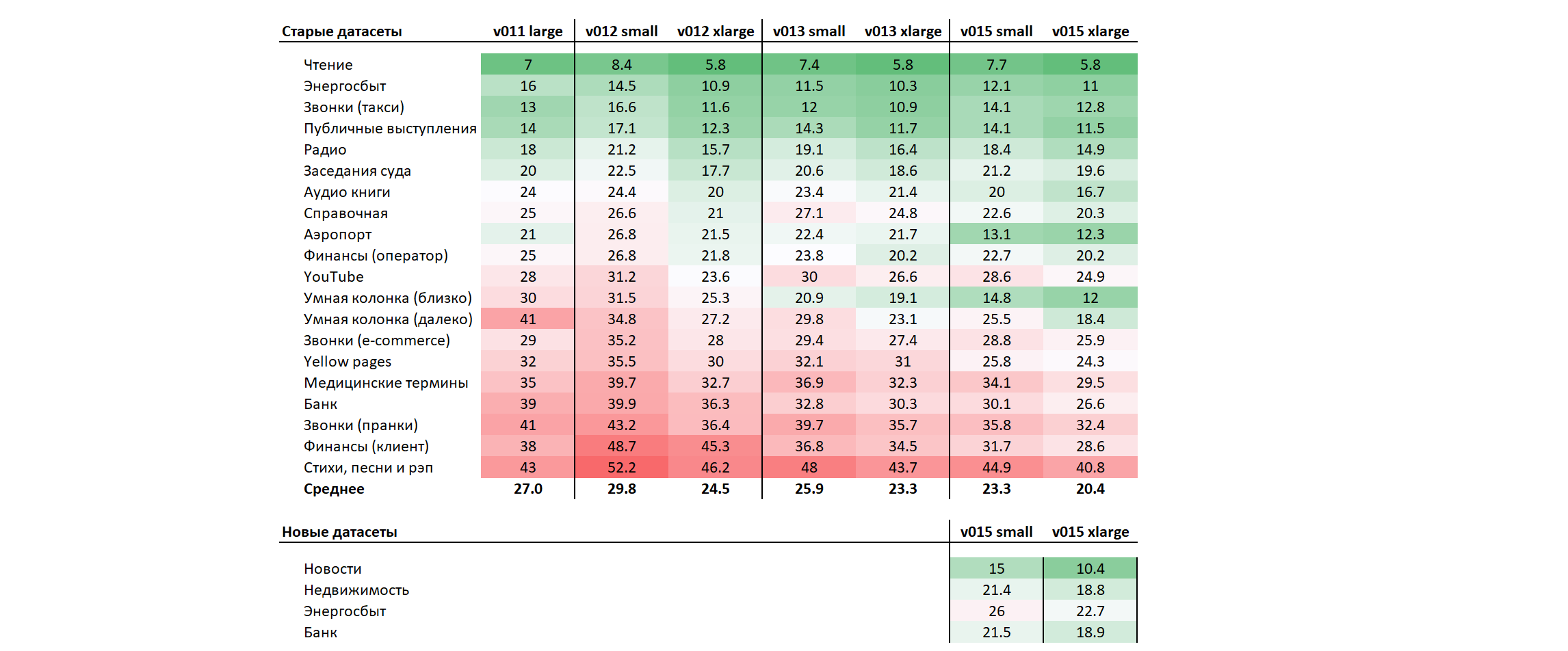
Основные моменты:
- В среднем качество растет;
- На звонках качество существенно растет;
- Появились новые валидационные датасеты (еще предстоит их немного почистить и переразметить, реальные метрики скорее всего на ~5 пп лучше);
- На такси скорее всего мы уперлись в лимиты нашего пост-процессинга (акустическая модель в этот раз была заметно лучше), нам предстоит большая работа именно над пост-процессингом в принципе;