💎 Как Улучшить Качество Распознавания Речи?
И пара слов про генерализацию систем STT.
Мы часто ведем беседы с заказчиками на тему того, как можно небольшим ресурсом (и не только) улучшать качество распознавания речи в конкретном домене. Чтобы лишний раз не повторяться, напишу тут краткое резюме.
Пара слов про генерализацию систем STT
Системы STT делятся на 2 типа:
- Которые хорошо или удовлетворительно работают вообще на любых (в разумных пределах) доменах и качество нужно только улучшать;
- Которые при старте обязательно нужно допиливать - размечать аудио, тренировать языковые модели;
Вообще тут нужно понимать, что качество сильно зависит от уровня шума и специфичности лексики. Пару раз мы сталкивались с тем, что люди сравнивают качество "общих" моделей, которые работают на "всем", и моделей, которые работают только на конкретных словах или на конкретном домене после доработки напильником.
Грубо говоря решение "А" стартует с 30% WER "на холодную", а решение "Б" на холодную вообще не стартует и работает только после вложения какого-то количества ресурсов, чтобы это решение работало на этом домене. Но после этого можно сразу получить допустим 25% WER.
Хорошо это или плохо? Все естественно относительно, но никто не сможет дать гарантии, что решение "Б", которое не генерализуется на старте и "подгоняется" под конкретный домен при малейшем от него отступлении продолжит иметь заявленное качество. Возникает также закономерый вопрос, какого качества можно достичь вложив ресурсы в кастомизацию решения "А". Что важно - рост качества решения "А" на одном домене как минимум не приведет к его падению на других.
Когда мы делали подход к снятию метрик систем, доступных на рынке, мы обратили внимание, что большая часть доступных решений относится к категории "Б" (ну и немного прослеживается кто на чем тренировал свои системы).
Вообще в общем случае такая "избирательность" не является чем-то плохим, просто при измерении метрик очень тяжело правильно соблюсти "научность" своего подхода, то есть банально нет гарантии что эти метрики будут соответствовать действительности в продакшене. Единственное, что по нашему мнению является показателем качества работы системы распознавания речи - это качество работы сразу на всех доменах одновременно.
Так как все-таки улучшить качество распознавания речи?
Мы сейчас умеем это делать четырьмя способами (от наимее затратного к наиболее затратному):
- Сборка доменного словаря терминов. Если у вас часто употребляются какие-то "особенные" слова, которые в обычном языке употребляются редко, но писать их нужно правильно - мы умеем просто добавлять такие словари. Это скорее добавляет качеству восприятия текста. Это самый простой и быстрый способ;
- Если у вас есть большой корпус текстов в вашем домене - то на них можно натренировать "маленькую" языковую модель и использовать ее одновременно с большой. Таким образом вырастет и качество и сохранится генерализация! Естественно можно комбинировать со способом (1);
- Если нужен еще более сильный прирост качества - можно просто разметить энное количество часов аудио. Обычно это от нескольких десятков до нескольких сотен часов. Это самый эффективный и проверенный способ. Его минус - время и затратность. Мы можем сделать это за вас, у нас все настроено для этого;
- Вообще в любом домене "рескоринг" гипотез, которые выдают модели, можно строить и на каких-то кастомных доменных эвристиках. В такси такой эвристикой, например, является наличие валидного адреса в тексте. Уже другой вопрос, что надо "вариться" довольно много времени в каком-то домене, чтобы это работало. Но иногда бывают и очень простые эвристики (например персональные данные можно искать по наличию цифр), которые тоже работают;
Естественно - все эти способы можно и нужно комбинировать.
| Способ | Затраты | Насколько получалось улучшить WER |
|---|---|---|
| Словарь терминов | 💵 | 1-2 процентных пункта |
| Дополнительная LM | 💵 | 4-5 процентных пунктов |
| Сбор и разметка аудио | 💵 💵 💵 | 8 - 10 процентных пунктов |
| Кастомные доменные эвристики | Может быть 💵 а может и 💵 💵 💵 💵 | Все очень по-разному |
Кейс 1 - словарь
Типовой пример - на такси словарь срезает 1-2 процентных пункта WER в каждом регионе.
Кейс 2 - дополнительная LM
Мы делали анализ сравнения "холодного" и "горячего" старта на конкретном домене (финансы). У нас получалось за счет комбинации словаря и дополнительной LM срезать дополнительные 4-5 процентных пунктов WER без особых инвестиций в разметку.
Кейс 3 - разметка аудио
Разметив менее 100 часов аудио мы смогли снизить WER на такси с 20% до 12%.
Кейс 4 - кастомные эвристики
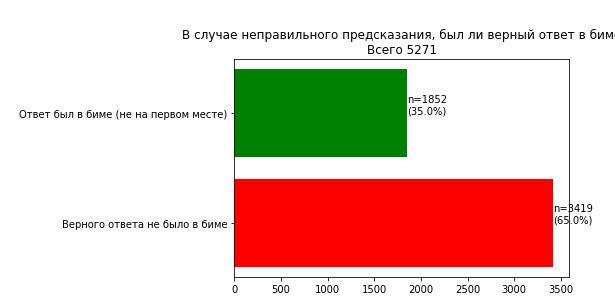
В распознавании речи пост-процессинг делается посредством сравнения вероятности гипотез, которые выдает модель. Довольно показательно - а что будет, если посчитать для неправильных предсказаний, в каком % из них верная гипотеза вообще была в списке, но не первом месте?
Мы сделали такой анализ для такси, и увидели, что среди всех ошибок порядка трети ошибок на самом деле на втором-третьем месте таки содержат верную гипотезу. Уже другой вопрос были ли ошибки в мелочах или в адресах, но используя свой доменный аналог геокодера из двух таких гипотез можно выбирать верную (на самом деле вычленять и проверять адреса оффлайн не так-то просто!).
Какой способ выбрать?
На самом деле тут не надо ничего выбирать. В идеале надо использовать все способы.
Просто как правило их внедрение будет просто разнесено по времени. Имея сильную STT модель, разметка даже 50 часов не является очень большим расходом.