🥇2023 - Сравнение Систем Распознавания Речи на Рынке РФ
Наконец-то пришло время обновить наше исследование качества систем распознавания речи на рынке РФ. Лучше поздно, чем никогда! С момента прошлого исследования утекло много воды … и мы думали, что мы не добежим до обновления, но таки добежали.
По сравнению с предыдущим исследованием изменилось следующее:
- Мы не стали опрашивать Google;
- На рынок с распознаванием речи вышли VK и якобы МТС, но нам не удалось продраться через тернии в случае первых и получить ключ с объемами достаточными для исследования, а в случае со вторыми кажется там была форма для лидов, на которую и нам не ответили;
- Опять же добавилось много валидационных сетов из разных реальных доменов;
- Опросы сервисов проводились с октября 2022 года (Яндекс и Тинькофф) по январь 2023 года (Сбер), ниже опишу почему;
- Пропускную способность сервисов в этот раз не тестировали;
Изменения Методологии
Методология с прошлого раза практически не изменилась. Единственный важный момент - в этот раз мы долго возились с сервисом Сбера (кажется теперь он "под Салютом", там провели какую-то реорганизацию), потому что мы думали, что нам хватит синхронного АПИ, но пришлось откатиться на потоковое из-за отсутствия достаточного числа флагов в первом.
В общем случае мы постарались дать максимально благоприятные условия для всех сервисов. И в первую очередь в случае Сбера подкручивали параметры запросов, пока точно не убедились, что всё распознается максимально качественно и нет технических ошибок именно в вызове распознавания. В частности проблемы были с "подтеканием" английского языка в русский (туда где точно нет английских слов). Также в отличие от других сервисов пришлось слать аудио с частотой дискретизации 8 и 16 kHz в разные модели.
Сухие метрики
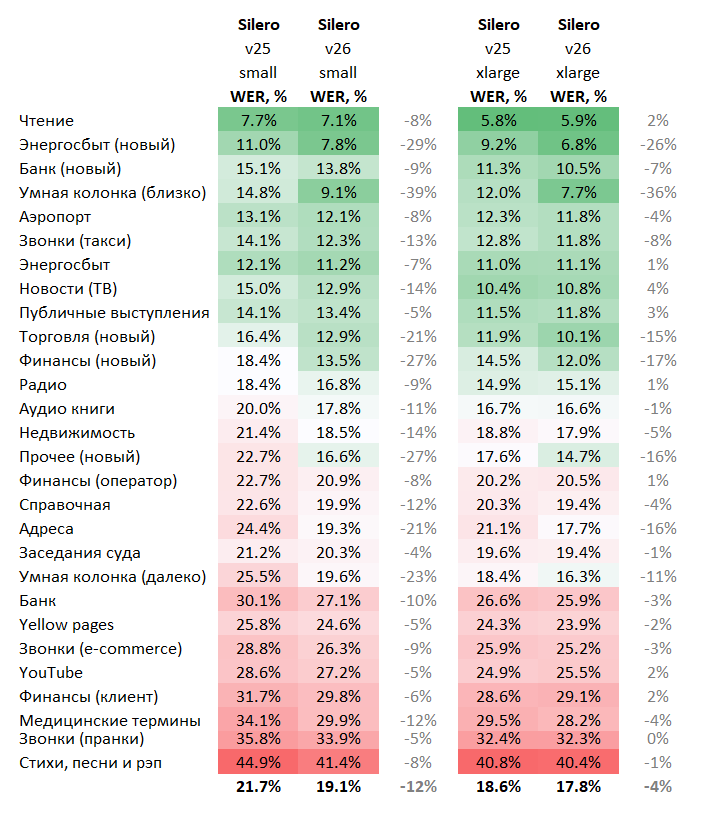
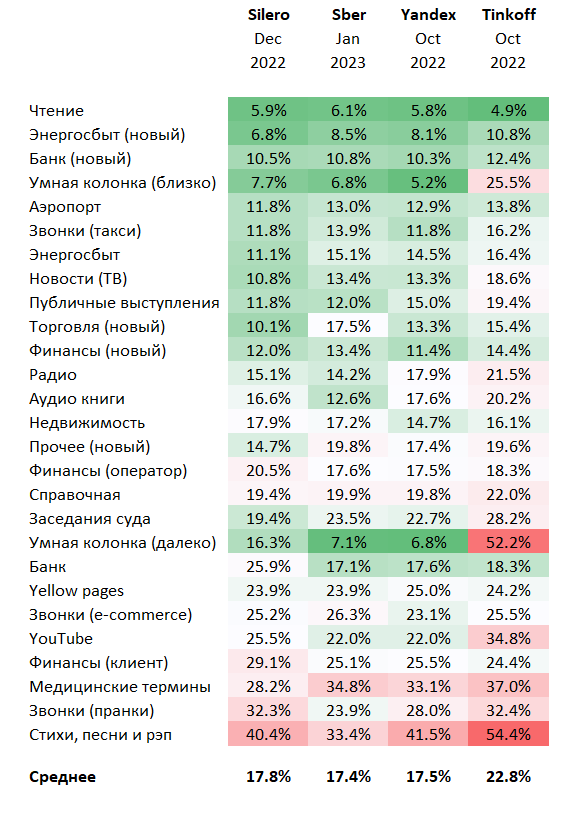
Поскольку методологию описывать заново не будем, постараюсь учесть прошлые ошибки и представить результат максимально сжато и наглядно. Основная метрика - WER (word error rate), выраженный в виде процентов для наглядности:
Краткий анализ
Во-первых, все сервисы сильно подросли по своим метрикам с прошлого раза. Сразу в глаза бросается большое отличие метрик Сбер и Яндекса на датасетах "умной колонки". В принципе логично и предсказуемо. В остальном наблюдается некоторая конвергенция результатов. Местами можно разглядеть некоторые "точки роста" и на каких данных учились модели, но самый большой основной вывод - Сбер сделал свои модели более-менее всеядными. В прошлый раз там был сильно больше разброс по показателям. Но тут можно резонно поиронизировать на тему того, что мы не знаем какие огромные расходы, модели и суперкомпьютеры стоят за этим АПИ. В глаза также бросается то, что в отличие от всех остальных в этот раз Tinkoff не показал существенного роста метрик.
Конвергенция маленьких моделей
Сущестенным также является то, что наша маленькая модель буквально "дышит" в спину большой и что она показала существенный рост и в этот раз, гораздо более заметный, чем рост "большой" модели: